SQL Server 2012 实施与管理实战指南Note:数据库空间管理
SQL Server 2012 实施与管理实战指南Note:数据库空间管理
数据库以数据文件和日志文件的形式保存。
在数据库空间管理上经常会遇到的问题:
- 数据文件(Data File)空间用尽
- 日志文件(Log File)不停增长。
- 数据文件空间无法收缩
- 自动增长(Auto grow)和自动收缩(Auto shrink)。
数据文件的空间使用和管理
数据文件类型:
主数据文件
.mdf存储指向数据库中的其他文件路径
每个数据库都有一个主数据文件
辅助数据文件
.ndfname(逻辑文件名)
文件在SQL Server里的名字,符合SQL Server标识符规则,唯一。
physical_name(物理文件名)
文件在操作系统里的名字和路径,符合操作系统文件命名规则
数据文件存储结构
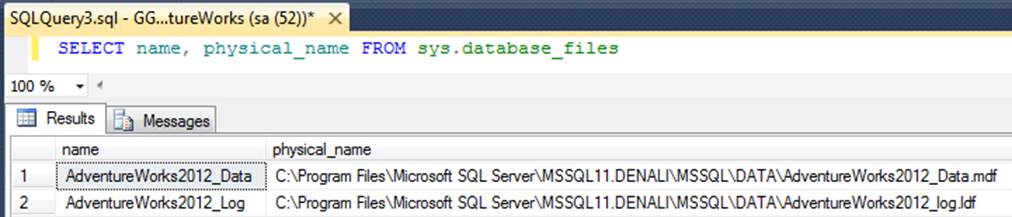
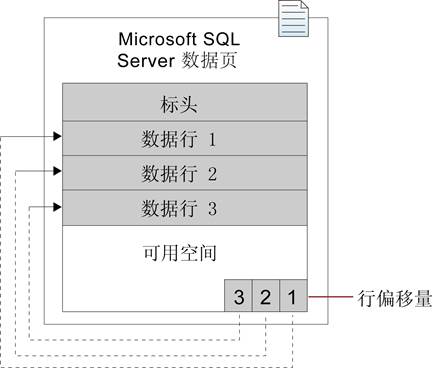
页(Page)
SQL Server中数据存储的基本单位是页
数据文件占据的磁盘空间从逻辑上划分成页(0到n连续编号)
SQL Server读取或写入数据的最小单位是以8 KB为单位的页
页头
- 每页开头的96字节
- 储存包括页码,页类型,页的可用空间,拥有该页的对象的分配单元ID等有关页的系统信息
不同类型的数据,存储在不同类型的页面里
页 类 型 内 容 Global Allocation Map(GAM) GAM在数据文件中的第三个页上。文件和页编号为(1:2)。它用bit位来标识相应的区(extents)是否已经被分配。它差不多能标识约64000个区(8k page * 8 bits per byte)。也就是4G的空间。如果数据空间超过4G,那么数据库会用另外一个GAM页来标识下一个4G空间。 Bit=1: 标识当前的区是空闲的,可以用来分配 Bit=0: 标识当前的区已经被数据使用了。 Shared Global Allocation Map (SGAM) SGAM在数据文件中的第四个页上。文件和页编号为(1:3)。它的结构和GAM是一样的。区别在于Bit位的含义不同。 Bit=1: 区是混合区,且区内至少有一个页是可以被用来分配的 Bit=0: 区是统一区,或者是混合区但区内所有的页都是在被使用的 Page Free Space 存储本数据文件里所有页分配和页的可用空间的信息。 Index Allocation Map 表或索引所使用的区的信息 Bulk Changed Map 自最后一条BACKUP LOG语句之后的大容量操作所修改的区的信息 Differential Changed Map 自最后一条BACKUP DATABASE语句之后更改的区的信息 Data 用来存放数据 Row Overflow Page 当一条记录超过8000字节的时,这时候就要借助Row Overflow Page用来存放超出部分的数据 LOB 用来存放大型对象数据类型:text、ntext、image、nvarchar(max)、varchar(max)、varbinary(max)和xml数据。 数据页结构
在正常页上,数据行紧接着页的标头按顺序放置。
页的末尾是行偏移量表,对于页中的每一行,每个行偏移表都包含一个条目。
每个条目记录对应行的第一个字节与页首的距离。
行偏移表中的条目的顺序与页中行的顺序相反
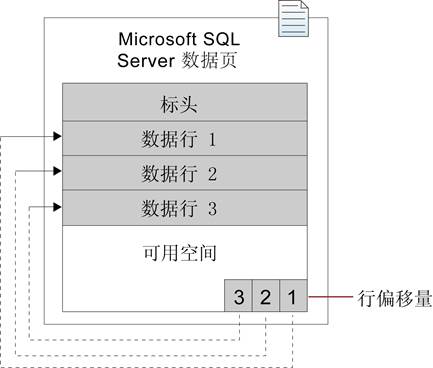
区(Extent)
- 8个物理上连续的页的集合,用于管理页
- 统一区
- 区内的8个页属于同一个表
- 混合区
- 区内的8个页分别属于至少两个不同的表
- 一个数据文件可以包含多个表
一个数据文件可能的结构:
大多数页面为Data、Text、Image类型,数据文件开头多为管理页面
| 页名 | Header | PFS | GAM | SGAM | Unused | Unused | DCM | BCM | … | Data | … |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 页号 | 1:0 | 1:1 | 1:2 | 1:3 | 1:4 | 1:5 | 1:6 | 1:7 | … | 1:1400 | … |
表存储结构
SQL Server通过每个页面的96个字节的页头和系统表,从逻辑层面上,把表的存储结构管理起来。
表概念关系:
每张表会有一个对应的Object ID
每张表拥有一个或者多个partition
每个partition会有一个或者多个Heap or B-Tree(Hobt)
每个Hobt会有至多三个分配单元(Data,LOB,Row-Overflow)用于存放数据
每个分配单元可以有许多页
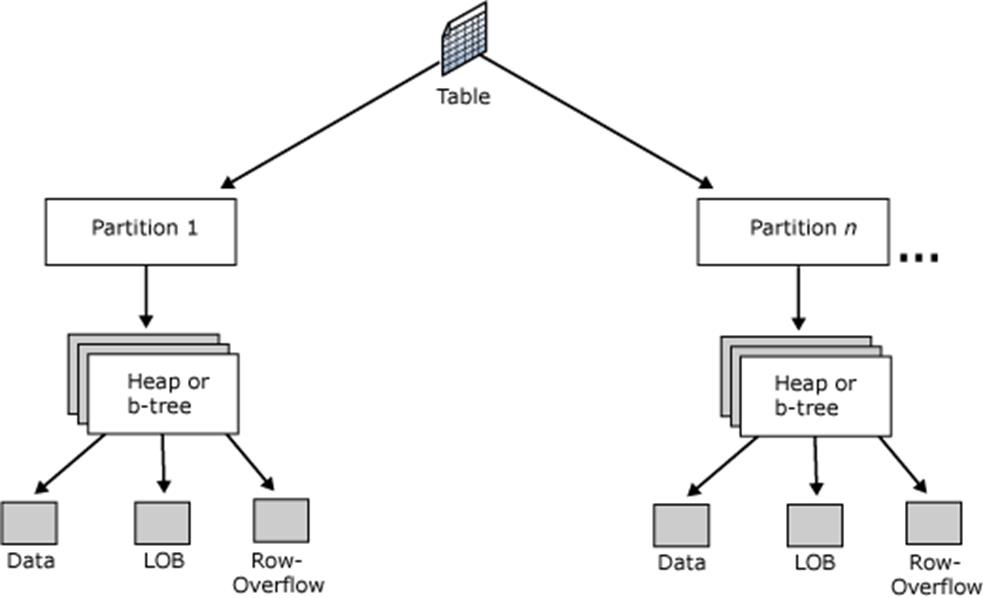
分配单元内数据页的组织方式:
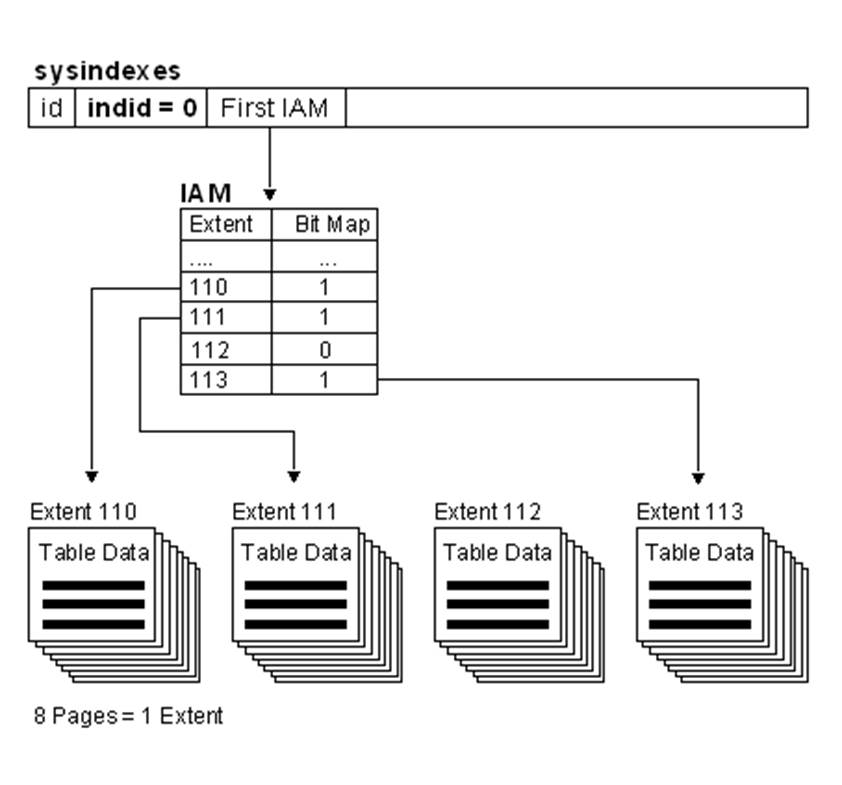
表没有任何索引
按Heap结构储存,只有一个partition,这个partition下面的每个分配单元都有一个连接指向IAM页,所有的IAM页是连接起来的
数据页之间没有任何关系,完全依赖IAM页组织
对于一个SELECT语句,SQL Server会首先查询IAM页,然后根据IAM页提供的信息,遍历每个区, 把区内符合条件的页返回
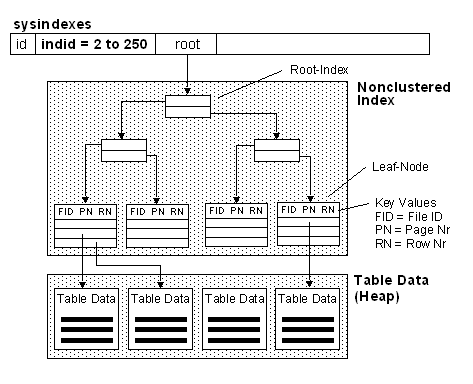
有非聚集索引而没有聚集索引的表
每个非聚集索都有一个相对应的partition,对于这个partition下面的每个分配单元都有一个连接指向root page(根页)
数据页之间通过前后指针互相联系
真正的数据是以堆(Heap)的结构存放的
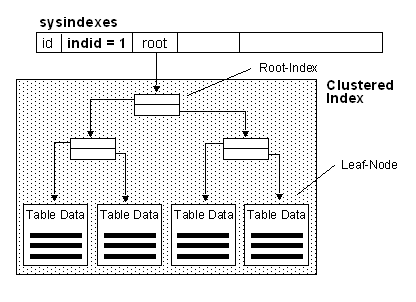
表有聚集索引
表中的聚集索引,对应的索引号是1,有一个对应的partition,对于这个partition下面的每个分配单元都有一个连接指向根页
叶子节点里存放的是真正的数据
案例:跟踪索引的存储结构
跟踪AdventureWorks2019中表Employee的空间使用。
得到表Employee的object_id:
1 | |

可以看到object_id是1893581784.
查询表格中包含的partition:
1 | |

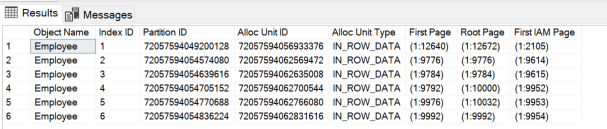
表Employee有6个partition,分别对应于不同的索引,每个partition有290条记录。hobt_id用来表示在该partition内heap
或 B树结构的标识。
查询partition编号5的分配单元信息:
1 | |

查询结果说明,对于partition_id = 72057594054770688,只有一个分配单元,用于存放数据页(IN_ROW_DATA),大小为25个page,其中数据页为2个页。
查询更加详细的分配单元信息:
1 | |

可以看到,根页的位置是0x302700000100,使用倒序解码,一次去一个字节(两位),字节中顺序不变,解码为00 01 00 00 27 30,前面两个字节表明的是所在的文件组编号,后面的4个字节表明页的编号,所以页面编号是(1,10032)
输出一定格式的指定页面:
DBCC PAGE 命令,使用前需要打开跟踪标志3604
1 | |
输出的结果如下:
1 | |
BUFFER标识该数据页在内存中的位置
PAGE HEADER显示了页头的信息
这里
m_prevPage = (0:0) m_nextPage = (0:0)可以看出这页是根页部分页头属性解析
页头属性 解析 m_pageID 页的编号 m_headerVersion 页头格式的版本,这个值是1 m_type 页的类型 1:表明是数据页。包括heap结构的数据,和聚集索引里B树结构的最底层页 2:索引页。包括聚集索引里B树结构的非底层页和非聚集索引的所有页 其他页类型,在此暂不提及。 m_typeFlagBits 基本上用不到 m_level 在B树结构中的层级。最底层的层级是0. m_flagBits 页的属性。如0x200表明页有checksum检查 m_prevPage, m_nextPage 在B树结构的同一层级数据页之间,互相通过m_prevPage和m_nextPage连接起来。 m_slotCnt 当前页中,有多少条记录 m_freeCnt 这是当前页中,还剩下多少空间,以字节为单位 m_lsn 这是当前页的所有记录中,最后一个改变相对应的日志记录号(Log Sequence Number)
注意这里第一个offset正好是96,对应页头信息
1
2
3Row - Offset
1 (0x1) - 123 (0x7b)
0 (0x0) - 96 (0x60)非聚集索引键指向的内容
1
2
3
4
5
6
7
8Slot 0, Offset 0x60, Length 27, DumpStyle BYTE
...
0000000000000000: 26f82600 00010001 001b0031 00300037 00300038 &ø&........1.0.7.0.8
0000000000000014: 00310030 003000 .1.0.0.
Slot 1, Offset 0x7b, Length 27, DumpStyle BYTE
...
0000000000000000: 26002700 00010001 001b0038 00370032 00360038 &.'........8.7.2.6.8
0000000000000014: 00380033 003700 .8.3.7.对于
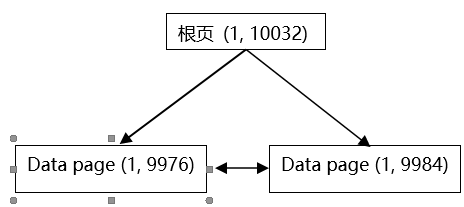
10708100,所指向的页面位置是f82600 000100,即(1, 9976)1
2
3DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2019', 1, 9976, 1)
DBCC TRACEOFF(3604)在Page Header可以发现,这一页在树的边缘,下一页页是(1:9984)
1
m_prevPage = (0:0) m_nextPage = (1:9984)可以看到一共有255个slot,即这个页面有255个child node
对于
87268837,所指向的页面位置是02700 000100,即(1, 9984),与上述发现相符1
2
3DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2019', 1, 9984, 1)
DBCC TRACEOFF(3604)在page header可以发现,这一页在树的另一边缘,前一页是(1:9976)
1
m_prevPage = (1:9976) m_nextPage = (0:0)可以看到一共有35个slot
如果我们查看对于Employee这个object,index=5的时候,对应的信息是NationalIDNumber
1
SELECT * FROM sys.indexes Where object_id = 1893581784
直接查看NationalIDNumber,我们可以发现,一共有290=255+35行,10708100和87268837属于NationalIDNumber。
1
SELECT NationalIDNumber FROM HumanResources.Employee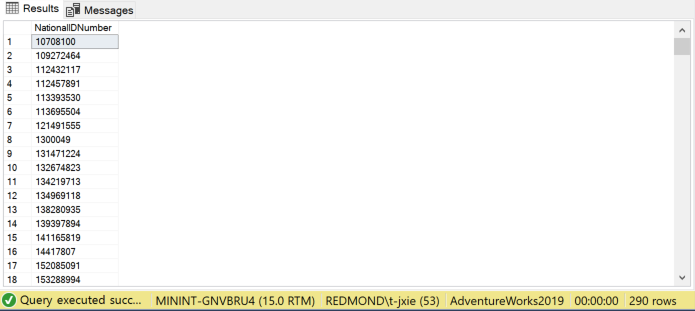
案例:使用sp_AllocationMetadata查看分配单元信息
Reference Inside The Storage Engine: sp_AllocationMetadata - Paul S. Randal (sqlskills.com)
创建procedure
1 | |
在另外的连接中执行
1 | |
即可查看
日志文件的空间使用和管理
每个数据库都有事务日志,用于记录所有事务以及每个事务对数据库所做的修改。
SQL Server对数据页的插入、修改和删除,是对缓冲区高速缓存(内存)中的页副本进行操作,操作完成后就提交事务,当数据库中出现检查点或缓冲区不够时,才写入磁盘。
SQL Server会确保在提交事务时或之前就将日志记录写入磁盘。
如果日志文件缺失或者损坏,将等同于数据库损坏。
刷新页:将修改后的数据页从高速缓冲存储器写入磁盘
脏页:在高速缓存中修改但尚未写入磁盘的页
日志文件组织方式:
- 每一物理日志文件由多个虚拟日志单元组成
- 虚拟日志单元没有固定大小
- 一个物理日志文件所包含的虚拟日志单元数不固定
- 管理员不能配置或设置虚拟日志单元的大小或数量
- 一个虚拟日志单元可以分成很多块,块内有很多具体的日志记录
- 对于每条日志记录,都有一个LSN(Log Sequence Number)编号
- 虚拟日志单元(Virtual Log File)的序列号:虚拟日志单元中块的编号:块中日志记录的编号
- 如对于某个LSN,其编号为0000001D:000000FD:0002,这表明这个LSN是属于虚拟日志 0000001D,在该虚拟日志中属于块000000FD, 然后在该块中对应记录2
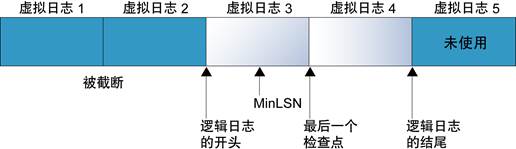
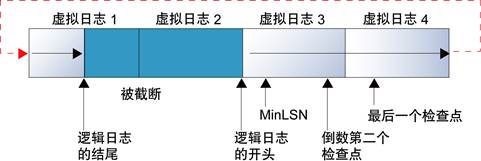
事务日志文件结构:
回绕
当创建数据库时,逻辑日志文件从物理日志文件的始端开始,新日志记录被添加到逻辑日志的末端,然后向物理日志的末端扩张,扩张到物理日志文件末端时,回绕到始端
查看日志文件中的信息:
DBCC LOG
1
2
3# DBCC LOG(<db_id|db name>, <formart_id>)
# <db_id|db name>:目标数据库编号或者是数据库名
# <format_id>:DBCC LOG命令翻译和解释日志记录的方式,一般使用31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 创建测试数据库,观察记录
CREATE DATABASE [TESTLOG]
GO
USE [TESTLOG]
GO
CREATE TABLE [TEST] (
[ID] int,
[name] nvarchar(50)
)
GO
INSERT INTO [TEST] VALUES (1, 'aaaa')
UPDATE [TEST] set [name] = 'xxxx' where [ID] = 1
GO
DBCC TRACEON(3604)
GO
DBCC LOG(TESTLOG,3)
GO
ApexSQL Log
数据库的更新操作:
- 数据库日志文件记录了旧值和新值
- 行级别操作
- Redo就是用新的值覆盖
- Undo就是用旧的值覆盖
- DELETE和TRUNCATE
- 使用DELECT删除表,是行级别的删除,LSN编号不同,整个DELECT语句是一个事务,所以事务编号相同
- 使用TRUNCATE删除表,不记录日志
- 删除记录量大的表,避免产生大量日志文件
- 但是不能Undo
SQL Server的日志记录特点:
- 日志记录的是数据的变化,面向数据库服务
- 每条记录都有它唯一的编号(LSN),并且记录了它属于的事务号
- 日志记录的行数和实际修改的数据量有关,修改越多,日志行数越多
- 日志记录了事务发生的时间,但是不记录发起者的程序名称和客户端信息
- SQL Server能够从日志记录里面读到数据修改前的值和修改后的值
空间使用计算方法
| 命 令 | 精确单位 | 性能影响 | 准确性 |
|---|---|---|---|
| DBCC SHOWFILESTATS | 区 | 无 | 基本准确 |
| sp_spaceused | 页 | 无 | 有时不准确 |
| sp_spaceused + updateusage | 页 | 稍有 | 基本准确 |
| sys.dm_db_partition_stats | 页 | 无 | 有时不准确 |
| DBCC SHOWCONTIG | 页/区 | 有 | 准确 |
空间使用计算方法
sp_spaceused1
2
3
4
5
6
7# 显示行数、保留的磁盘空间以及当前数据库中的表、索引视图等数据库对象所使用的磁盘空间
# 若不指定objectname,则返回整个数据库的结果
sp_spaceused [[ @objname = ] 'objname' ]
[, [ @updateusage = ] 'updateusage' ]
[, [ @mode = ] 'mode' ]
[, [ @oneresultset = ] oneresultset ]
[, [ @include_total_xtp_storage = ] include_total_xtp_storage ]
统计单位:页
局限:
- 数据库发生较大变化后,结果常常不准确
- 使用
sp_spaceused + updateusage来要求SQL Server为这句指令更新管理视图里的统计信息 - 但消耗资源
- 使用
- 无法统计tempdb
- 一次只能查询一个对象
- 可以通过直接查询sys.dm_db_partition_stats以及相关的管理视图来解决
- 数据库发生较大变化后,结果常常不准确
Management Studio --> Right click on data base --> Reports --> Standard Reports --> Disk Usage
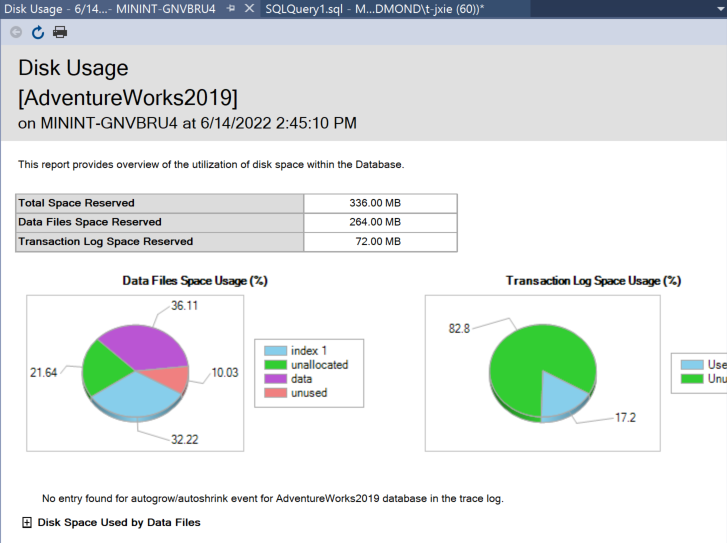
调用了
DBCC ShowFileStats命令
DBCC ShowFileStats- 按照区的使用情况统计数据文件的使用大小
- 从系统分配页面(GAM、SGAM)读取区分配信息以计算数据库数据文件区的总数和已使用的区的总数。
- 比较准确可靠
- 不会增加额外系统负担

sys.dm_db_partition_stats统计单位:页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 对数据库内所有对象进行统计
SELECT o.name ,
SUM (p.reserved_page_count) AS reserved_page_count,
SUM (p.used_page_count) AS used_page_count,
SUM (
CASE
WHEN (p.index_id < 2) THEN (p.in_row_data_page_count +
p.lob_used_page_count + p.row_overflow_used_page_count)
ELSE p.lob_used_page_count + p.row_overflow_used_page_count
END
) AS DataPages,
SUM (
CASE
WHEN (p.index_id < 2) THEN row_count
ELSE 0
END
) AS rowCounts
FROM sys.dm_db_partition_stats p INNER JOIN sys.objects o
ON p.object_id = o.object_id
GROUP BY o.name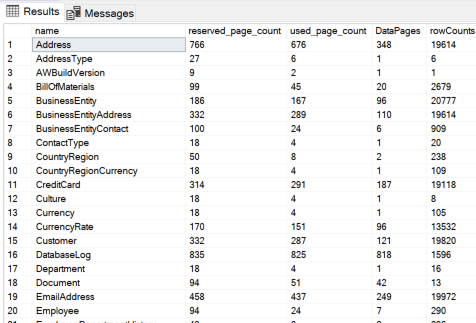
DBCC SHOWCONTIG- 统计某张表(或索引)用了多少页面、多少区,甚至页面上的平均数据量
- 而扫描的过程中,SQL
Server是要加锁的;要得到的结果越精确,扫描的范围就越大
- LIMITED模式运行最快,扫描的页数最少
- SAMPLED模式将返回基于索引或堆中所有页的1%样本的统计信息
- DETAILED模式将扫描所有页并返回所有统计信息
- 最精确的方法,但是在数据库处于工作高峰时应避免使用

分析日志文件存储空间
DBCC SQLPERF(LOGSPACE)
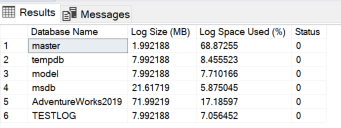
- 结果返回所有数据库大小,使用比率
- 对性能没有影响
- 结果总是准确
- 可随时运行
TEMPDB的空间使用
Tempdb系统数据库是一个全局资源,主要用于保存:
用户对象
由用户显式创建
可位于用户会话的作用域中;可位于创建对象所用例程的作用域中
例程可以是存储过程、触发器或用户定义函数
包括:
- 用户定义的表和索引
- 系统表和索引
- 全局临时表和索引
- 局部临时表和索引
- table变量
- 表值函数中返回的表
内部对象
- SQL Server数据库引擎创建,用于处理SQL Server语句
- 可以在语句的作用域中创建和删除
- 每个内部对象至少使用9页:一个IAM页,一个8页的区
- 包括:
- 用于游标或假脱机操作以及临时大型对象(LOB)存储的工作表
- 用于哈希联接或哈希聚合操作的工作文件
- 用于创建或重新生成索引等操作(如果指定了SORT_IN_TEMPDB)的中间排序结果,或者某些GROUP BY、ORDER BY或UNION查询的中间排序结果
版本存储区
- 数据页的集合,包含支持使用行版本控制的功能所需的数据行
- 主要用来支持快照(Snapshot)事务隔离级别
- 主要有两个版本存储区:公用版本存储区和联机索引生成版本存储区
Tempdb空间使用跟踪
使用管理视图sys.dm_db_file_space_usage,包含的字段有:
| 列 名 | 数据类型 | 说 明 |
|---|---|---|
| database_id | smallint | 数据库ID |
| file_id | smallint | 文件ID。 file_id映射到sys.dm_io_virtual_file_ stats中的file_id,并映射到sys.sysfiles中的fileid |
| unallocated_extent_ page_count | Bigint | 文件的未分配区中的总页数。 不包括已分配区中的未使用页 |
| version_store_ reserved_page_count | Bigint | 为版本存储分配的统一区中的总页数 |
| user_object_reserved_ page_count | bigint | 从统一区为数据库中的用户对象分配的总页数。计数中包括已分配区中未使用的页。 可使用sys.allocation_units目录视图中的total_pages列来返回用户对象中每个分配单元的保留页计数 |
| internal_object_ reserved_page_count | bigint | 从统一区为文件中的内部对象分配的总页数。计数中包括已分配区中未使用的页。 不存在可返回每个内部对象的页计数的目录视图或动态管理对象 |
| mixed_extent_page_ count | bigint | 文件的已分配混合区中的已分配和未分配总页数。混合区包含分配给不同对象的页。此计数包含文件中的所有IAM页 |
如何设置tempdb初始大小:
- 基于生产环境进行测试
- 设置tempdb的自动增长
- 模拟各个单独的查询或工作任务,同时监视tempdb空间使用
- 模拟执行一些系统维护操作,例如,重新生成索引,同时监视tempdb空间
- 使用前面2和3步中tempdb空间使用值来预测总的工作负荷下,会使用多少空间;并针对计划的并发度调整此值
- 根据第4步得到的值,设置tempdb在生产环境下的初始大小。同时也开启自动增长
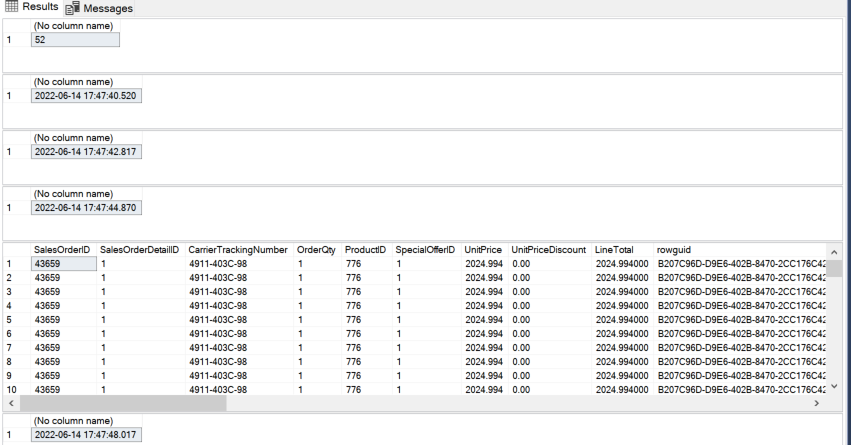
案例:通过脚本监视tempdb空间使用
以一定的间隔时间运行能够监视系统运行状况的DBCC命令、查询管理视图(DMV)以及管理函数(DMF)等,把结果输出到一个文件里。
1 | |
1 | |
数据文件的收缩
删除数据
DELETE命令并不能完全释放表格或索引的数据结构以及它们申请的页面
删除数据释放空间方法:
- 在表格上建立聚集索引
- 如果所有数据都不要了,要使用TRUNCATE TABLE而不是DELETE
- TRUNCATE TABLE释放数据页,不记录事务日志
- TRUNCATE TABLE始终锁定表和页,而不是锁定各行
- TRUNCATE TABLE不留下空页
- TRUNCATE TABLE删除表中的所有行,但表结构及其列、约束、索引等保持不变
- 如果表格本身不要了,就直接DROP TABLE
收缩数据库
准备工作:
- 确认收缩量的大小不超过当前文件的空闲空间的大小,释放出相应空间
- 主数据文件(Primary File)是不能被清空的。能被完全清空的只有辅助数据文件
- 如果要把一个文件组整个清空,要删除分配在这个文件组上的对象(表格或索引),或者把它们移到其他文件组上
DBCC SHRINKDATABASE
收缩指定数据库中的所有数据文件和日志文件的大小,不能对每个文件指定操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18DBCC SHRINKDATABASE
( database_name | database_id | 0
[ , target_percent ]
[ , { NOTRUNCATE | TRUNCATEONLY } ]
)
[ WITH
NO_INFOMSGS ,
{
[ WAIT_AT_LOW_PRIORITY
[ (
<wait_at_low_priority_option_list>
)]
]
}
]
< wait_at_low_priority_option > ::=
ABORT_AFTER_WAIT = { SELF | BLOCKERS }
DBCC SHRINKFILE
收缩当前数据库指定数据文件或日志文件的大小
本质是把使用过的区前移,将没有在使用的区从文件中移除以达到减小文件大小的效果。当很多空页面分布在各个区,导致没有很多空的区的时候,收缩效果会不好。
运行时会扫描数据文件并对正在读的页面加锁,对性能有一定影响;运行时其他用户可以对数据库进行读写操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19DBCC SHRINKFILE
(
{ file_name | file_id }
{ [ , EMPTYFILE ]
| [ [ , target_size ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ]
}
)
[ WITH
NO_INFOMSGS ,
{
[ WAIT_AT_LOW_PRIORITY
[ (
<wait_at_low_priority_option_list>
)]
]
]
< wait_at_low_priority_option > ::=
ABORT_AFTER_WAIT = { SELF | BLOCKERS }
案例:收缩数据库
创建数据库,并创建一个每一行都会占用一个页面的表格,由于表格上没有聚集索引,表格以堆存储。
1 | |
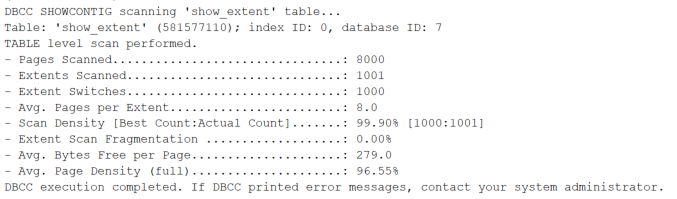
可以看到占用了8000页
删除每个区里面的7个页面,只保留a=5的这些记录
1 | |

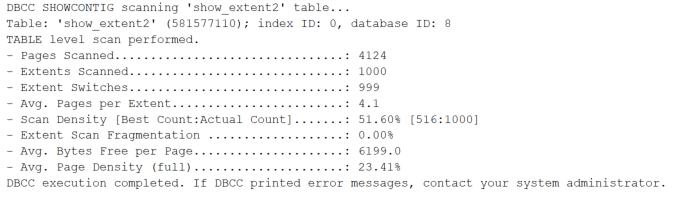
可以发现,这里Pages Scanned说一半以上的pages还在使用,Scan Density
说明区里页的占用率不高,松散,Extents Scanned说明所有区都还在被使用。
这个时候如果进行收缩
1 | |

会发现是没有什么效果的。
如果重建索引,把页面重新排列一次
1 | |
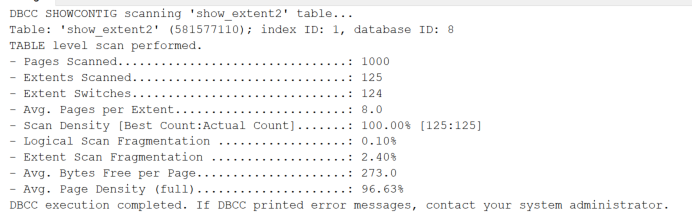
可以发现,重建索引后,由于之前以堆存放的页面以B数重新排列,被占用的页面释放出来,被占用的区也释放出来。密度也增加了。这个时候再去收缩就有效果了。
1 | |

如果不想建聚集索引,可能只有把这张表的数据先移走,然后清空表格,再把数据插回来
对于区中存放text或者image等数据(SQL Server使用单独页面存放),重建索引不会影响到这些数据,应该怎么解决呢?
使用DBCC EXTENTINFO打出数据文件里的所有区的分配信息,然后计算每个对象理论上区的数目和实际的数目。如果实际数目远大于理论的数目,那这个对象就是碎片过多,考虑重建对象。
日志文件不停地增长
SQL Server需要的日志记录
- 所有没有经过“检查点”的日志记录,经过检查点后会保证所有的“脏页”都被写入硬盘
- 对于不需要的日志记录,在每个检查点会进行截断,把这些记录占用的空间标志成可重用
- 做检查点的频率取决于服务器属性“Recovery Interval”
- 所有没有提交的事务所产生的日志记录,以及在它们之后的所有日志记录。
- 因为一个没有提交的事务可以在任何时候回滚,需要标记所有从这个事务开始的日志记录
- 所有要做备份的日志记录
- 有其他需要读取日志的数据库功能模块
- 事务型复制(Transactional Replication)
- 和数据库镜像(Database Mirroring)
日志文件不停地增长通常原因
- 数据库恢复模式不是简单模式,但是没有安排日志备份导致没有截断,无法释放空间
- 数据库上面有一个很长时间都没有提交的事务,导致一直记录日志
- 数据库上有一个很大的事务正在运行
- 数据库复制或者镜像出了异常
案例:日志增长原因定位
检查日志现在使用情况和数据库状态
1
2
3
4
5
6
7# 检查当前日志的使用百分比、数据库恢复模式和日志重用等待状态
DBCC SQLPERF(LOGSPACE)
GO
# 反映SQL Server认为的,不能截断日志的原因
SELECT name, recovery_model_desc, log_reuse_wait,log_reuse_wait_desc
FROM sys.databases
GO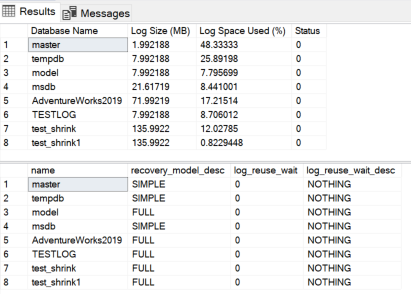
1. log_reuse_wait值 log_reuse_wait_desc值 0 NOTHING 当前有一个或多个可重用的虚拟日志文件 1 CHECKPOINT 自上次日志截断之后,尚未出现检查点,或者日志头部尚未跨一个虚拟日志文件移动范围(所有恢复模式) 2 LOG_BACKUP SQL Server在等待着日志备份。要求日志备份将日志标头前移(仅适用于完整恢复模式或大容量日志恢复模式)。 日志备份完成后,日志标头将前移,并且一些日志空间可能会变为可重新使用 3 ACTIVE_BACKUP_OR_ RESTORE 数据备份或还原正在进行(所有恢复模式)。 数据备份与活动事务的工作原理相同;数据备份运行时,将阻止截断 4 ACTIVE_TRANSACTION 事务处于活动状态(所有恢复模式)。 有一个用户开启了一个长时间运行的事务。在这种情况下,可能需要那个用户将事务提交或者回滚以后,才能释放空间。 事务被延迟(仅适用于 SQL Server 2005 Enterprise Edition 及更高版本)。“延迟的事务”是有效的活动事务,因为某些资源不可用,其回滚受阻。 5 DATABASE_MIRRORING 数据库镜像暂停,或者在高性能模式下,镜像数据库明显滞后于主体数据库(仅限于完整恢复模式) 6 REPLICATION 在事务复制过程中,与发布相关的事务仍未传递到分发数据库(仅限于完整恢复模式) 7 DATABASE_SNAPSHOT_ CREATION 正在创建数据库快照(所有恢复模式) 8 LOG_SCAN 正在进行日志扫描(所有恢复模式) 9 OTHER_TRANSIENT 此值当前未使用 检查最老的活动事务
如果日志的大部分都在使用中,而且日志重用等待状态是ACTIVE_TRANSACTION,需要检查最久未提交的事务是谁申请的
1
2
3# 返回的是当前数据库最久未被提交的事务
DBCC OPENTRAN
GO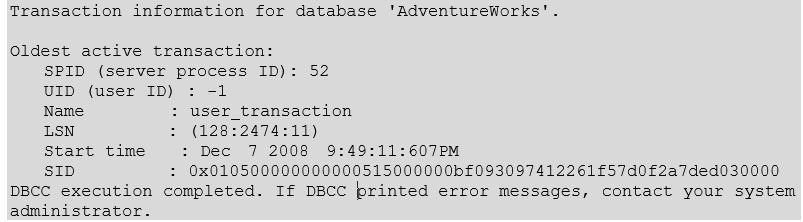
1
2
3
4
5
6# 查看来连接建立情况
SELECT st.text,t2.*
FROM sys.dm_exec_sessions AS t2, sys.dm_exec_connections AS t1
CROSS APPLY sys.dm_exec_sql_text(t1.most_recent_sql_handle) AS st
WHERE t1.session_id = t2.session_id
AND t1.session_id >50
1
2
3# 尝试关闭连接
# 如果一个连接正处于提交或者回滚的过程中,SQL Server会尊重它的执行而不去强行终止它
KILL 52
文件自动增长和自动收缩
数据文件和日志文件空间申请特点
数据文件
- 按所有文件空闲空间大小的比例分配
- 假设3个文件空闲空间是200:100:100,40 MB的数据就按照20 MB:10 MB:10 MB的比例写入了这3个文件
- 加入多个数据文件
- 必须保证同一个文件组里的所有数据文件都有基本一样大小的空闲空间以达到分散I/O负载的目的
- 如果文件全部写满
- 会选取其中一个文件(可能是任意一个)做自动增长,所有后面的数据都写入这个做了自动增长的文件里,直到这个文件再次写满,SQL Server要做下一次自动增长为止
- 很难达到I/O负载平衡的效果
日志文件:
- 按照严格的顺序写入
- 在一个时间点只写其中的一个文件。只有这个文件写满了,SQL Server才会写入另外一个
- 加入多个日志文件对性能基本不会有什么帮助
- 如果文件全部写满
- SQL Server自动增长当前的日志文件,以保证日志记录的连续性
数据库自增长设置
- 当某个操作触发了文件自动增长时,SQL Server会让那个操作等待。直到文件自动增长结束了,原先的那个操作才能继续进行
- 要设置成按固定大小增长以避免一次增长太多或者太少
- 要定期监测各个数据文件的使用情况,尽量保证每个文件剩余的空间一样大,或者是期望的比例。
- 设置文件最大值
- 发生自增长后,要及时检查新的数据文件空间分配情况
数据库自动收缩
- 不推荐
- 治标不治本
- 收缩后还是会增长
- 数据文件收缩会给文件带来更多的碎片
- 对性能有不小影响